About UDM2.1¶
Overview¶
Clouds and other atmospheric interference can have a significant impact on the usability and accuracy of Earth observation data. They can hinder the extraction of meaningful information from the images and complicate data analysis, leading to additional costs and reduced efficiency in research or commercial applications. It is for this reason that Planet provides a Usable Data Mask (UDM) with every published image.
UDM2.1 is the latest version developed by Planet, and it provides valuable information formatted as an 8-band GeoTIFF format. Each band within the UDM2.1 GeoTIFF corresponds to a different class of pixels, while two additional bands offer supplementary information. UDM2.1, classifies each pixel in an image as Clear, Cloud, Haze, Cloud Shadow or Snow. Every published PlanetScope or SkySat image has a corresponding UDM formatted as an 8-band GeoTIFF where each band maps to a different class, plus two additional bands providing additional information.
Key Differences Between UDM2.1 and UDM2.0¶
UDM2.1 significantly improves performance in classifying data when compared to the previous version of the mask, UDM2.0.
These are the key differences between UDM2.0 and UDM2.1:
- There is one haze class rather than two. The Heavy Haze class in UDM2.0 underperformed and was too commonly confused with the Cloud and Light Haze classes. Having a single haze class produces a more consistent and understood product.
- Clouds are defined as interference that are not seen through to the ground and haze is defined as any interference that is seen through to the ground. With this easily understood definition, Planet provides the most usable data.
Note
The formatting of the product has not changed from UDM2.0 to UDM2.1 and is delivered as an 8-band GeoTIFF. The prior Light Haze band (band 4) will be populated with the only Haze value and the values for the Heavy Haze band (band 5) and the heavy_haze_percent metadata will always be 0.
Availability - Date Ranges¶
Usable Data Masks are available for PlanetScope imagery starting from August 2018 globally, and specific agricultural regions from January 2018. A small percentage of PlanetScope imagery after August 2018 will not include the UDM2 asset. This is because of rectification or image processing failures.
Usable Data Masks are also available for the SkySat archive starting from 2017. In very rare instances, a UDM2 asset may not be available for specific SkySat items. As of November 29, 2023 all new PlanetScope and SkySat imagery will be processed by UDM2.1. Any imagery acquired prior to November 29, 2023 were processed by UDM2.0.
Metadata Fields¶
These metadata fields may be used to construct filters for searching Planet imagery. To learn more, refer to the Planet help page Search Filters.
UDM2.1-related metadata fields¶
| Field | Type | Value Range | Description |
|---|---|---|---|
| clear_percent | int | [0-100] | Percent of clear values in the dataset. Clear values represents scene content areas (non-blackfilled*) that are deemed to be not impacted by cloud, haze, shadow and/or snow. |
| clear_confidence_percent | int | [0-100] | percentage value: per-pixel algorithmic confidence in 'clear' classification |
| cloud_percent | int | [0-100] | Percent of cloud values in the dataset. Cloud values represent regions of a scene (non-blackfilled) that contain thick clouds. You cannot see ground objects through clouds. |
| heavy_haze_percent | int | [0-100] | Note: UDM2.1 does not include a heavy haze classification. Any non-zero values for this field were generated by the UDM2.0 product. Under UDM2.0’s definition: Percent of heavy haze values in the dataset. Heavy haze values represent scene content areas (non-blackfilled) that contain thin low altitude clouds, higher altitude cirrus clouds, soot and dust which allow fair recognition of land cover features, but not having reliable interpretation of the radiometry or surface reflectance. |
| light_haze_percent | int | [0-100] | Percent of haze values in the dataset. Haze values represent regions of a scene (non-blackfilled) with thin, filamentous clouds, soot, dust, and smoke. You can see ground objects through haze. |
| shadow_percent | int | [0-100] | Percent of cloud shadow values in the dataset. Shadow values represent regions of the scene (non-blackfilled) that are covered by shadows caused by clouds. |
| snow_ice_percent | int | [0-100] | Percent of snow and ice values in the dataset. Snow_ice values represent regions of the scene (non-blackfilled) that are hidden below snow and/or ice. |
| visible_percent | int | [0-100] | Visible values represent the fraction of the scene content (excluding the portion of the image which contains blackfill) which comprises clear, light haze, shadow, snow/ice categories, and is given as a percentage ranging from zero to one hundred. |
| visible_confidence_percent | int | [0-100] | Average of confidence percent for clear_percent, light_haze_percent, shadow_percent and snow_ice_percent |
* Blackfilled content refers to empty regions of a scene file that have no value
UDM2.1 Map Deliverable¶
The new UDM2.1 asset is delivered as a multi-band GeoTIFF file, with the following bands and values:
UDM2.1 Bands¶
| Band | Class | Pixel Value Range | Description |
|---|---|---|---|
| 1 | Clear | 0,1 | Regions of a scene that are free of cloud, haze, cloud shadow and/or snow |
| 2 | Snow | 0,1 | Regions of a scene that are covered with snow or ice |
| 3 | Cloud Shadow | 0,1 | Shadows caused by clouds or haze and not by mountains, buildings, or other terrain features |
| 4 | Light Haze | 0,1 | Regions of a scene with thin, filamentous clouds, soot, dust, and smoke. You can see ground objects through haze |
| 5 | Heavy Haze | 0,1 | UDM2.1 does not support a heavy haze class, but this class name persists to support functional backwards compatibility with UDM2.0. Pixels will never be classified as Heavy Haze with UDM2.1. |
| 6 | Cloud | 0,1 | Regions of a scene that contain thick clouds. You cannot see ground objects through clouds |
| 7 | Confidence | 0-100 | This is an indication of how confident the model that powers UDM2.1 is that a given pixel’s classification is correct |
| 8 | Unusable Pixels | – | Equivalent to the UDM asset. For the PlanetScope 8th Band, the bits are as follows. Bit 0: Black fill, Bit 1: Likely cloud, Bit 2: Blue (Band 2) is anomalous, Bit 3: Green (Band 4) is anomalous, Bit 4: Red (Band 6) is anomalous, Bit 5: Red Edge (Band 7) is anomalous, Bit 6: NIR (Band 8) is anomalous, Bit 7: Coastal Aerosol (Band 1) and/or Green-I (Band 3) and/or Yellow (Band 5) is anomalous. See Planet's Imagery Specification for complete details. |
Confidence Band Notes¶
Every pixel classification has a score associated with it and indicates how convinced the supervised segmentation model is that the pixel classification is correct. This can be used to help you define your own thresholds as to whether to accept a given pixel’s classification. For example, if you want to make sure that a pixel is clear before analyzing it, you can set a high confidence threshold for pixels classified as Clear.
Note
There will be times where the model is unequivocally convinced that a pixel is Clear, when in fact it is Cloudy. In these cases, we need additional training data to teach the model to adjust its classification. We encourage you to report any issues to your Customer Support Representative so Planet can continue to improve the product.
UDM2.1 Classification Methodology¶
Planet’s UDM2.1 classification approach is based on supervised machine learning techniques that use observation data from Planet-sensors to train a classification model.
UDM2.1 is powered by a modified UNET, a deep learning supervised segmentation model, that runs on 4-band (RGBNir) top-of-atmosphere radiance (TOAR) assets. This means tens of thousands of PlanetScope and Skysat images were hand-labeled to mark each pixel into one of the 5 classes noted above. The model was then trained using this labeled dataset so that it can classify new imagery into those same 5 classes.
To ensure that the truth scenes dataset are representative of the global catalog of Planet images, Planet draws from a diversity of satellites, scene content, seasonality, geography and cloud types to contribute to the truth scene curation and classification process.
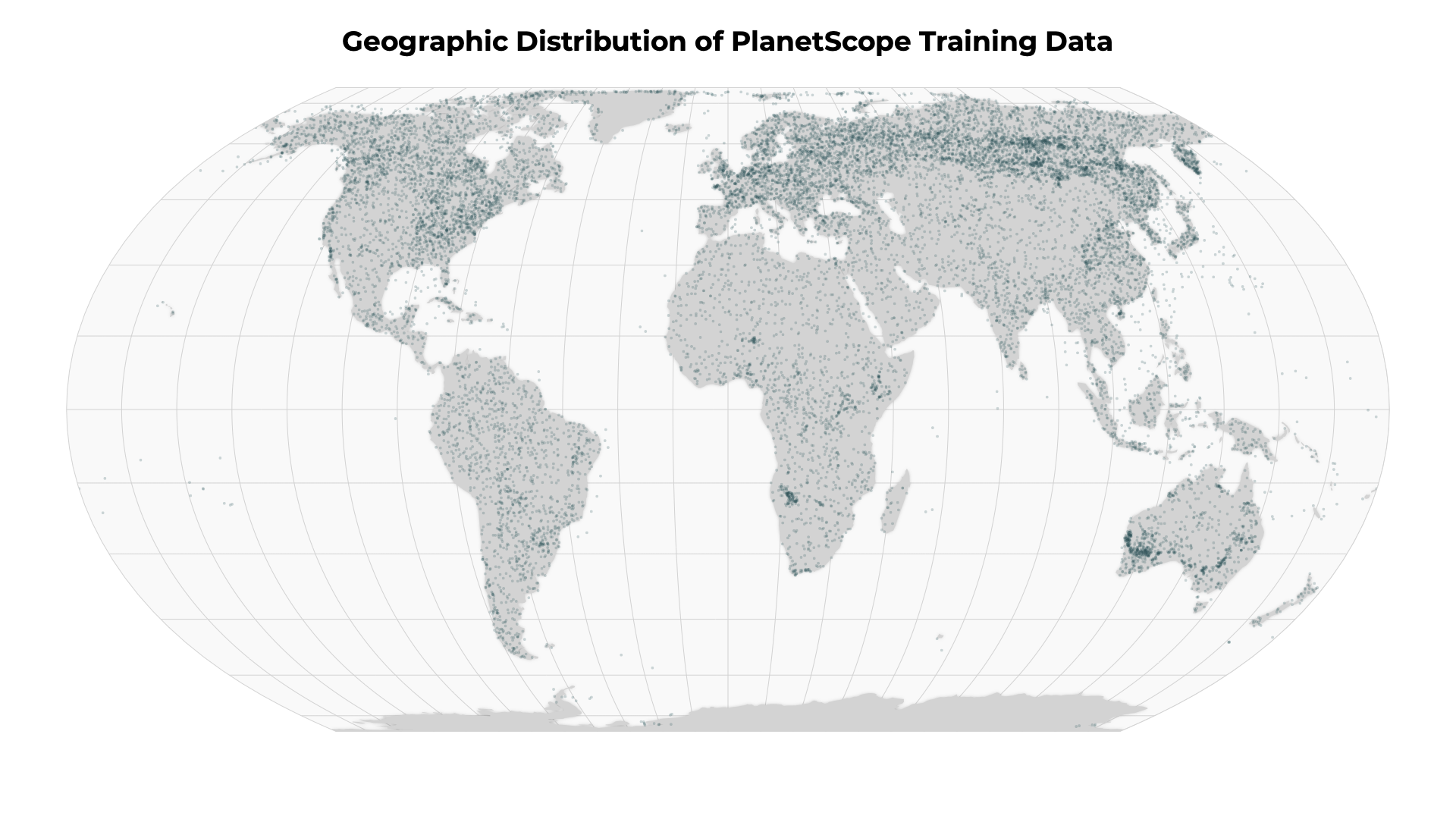
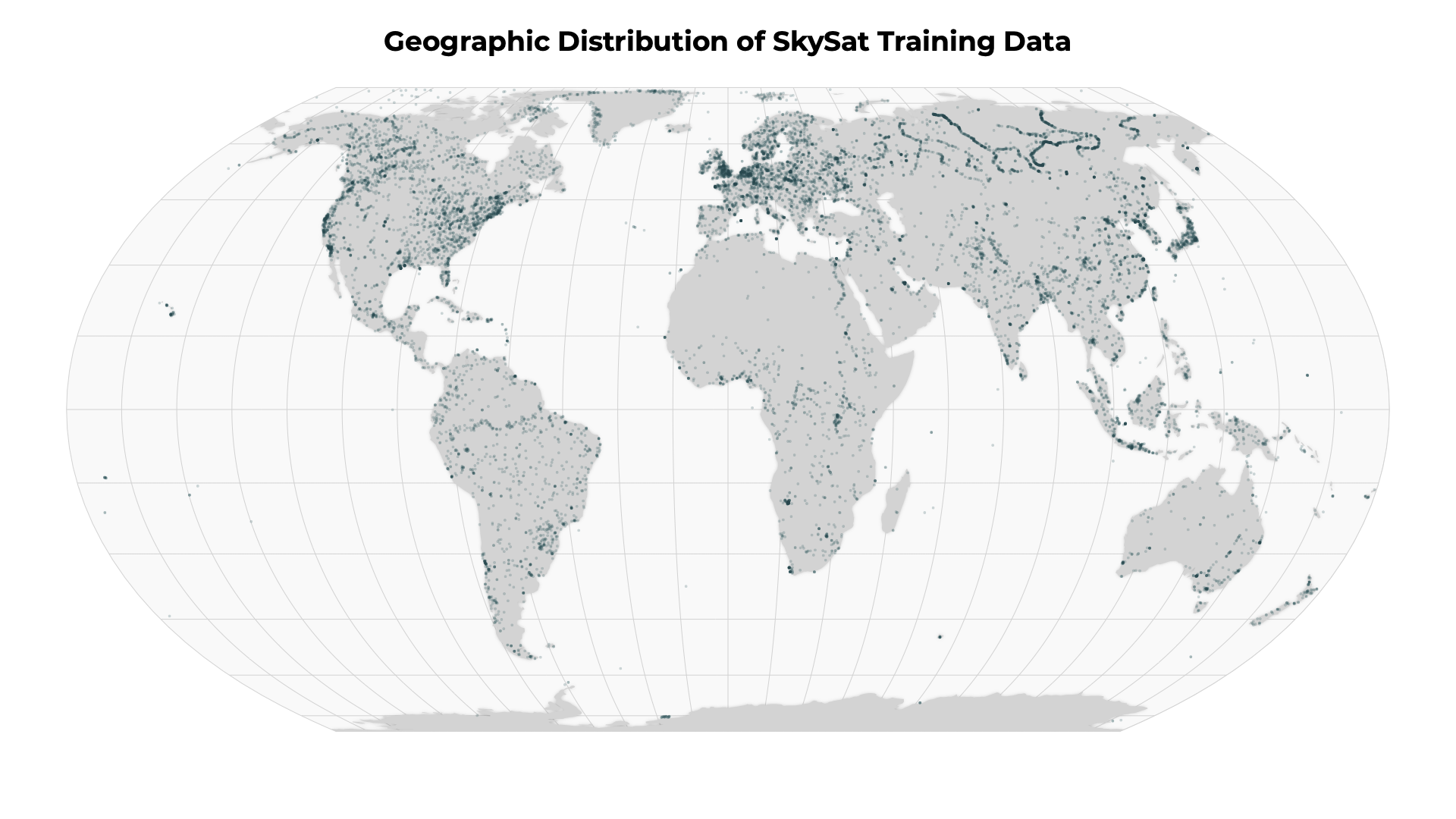
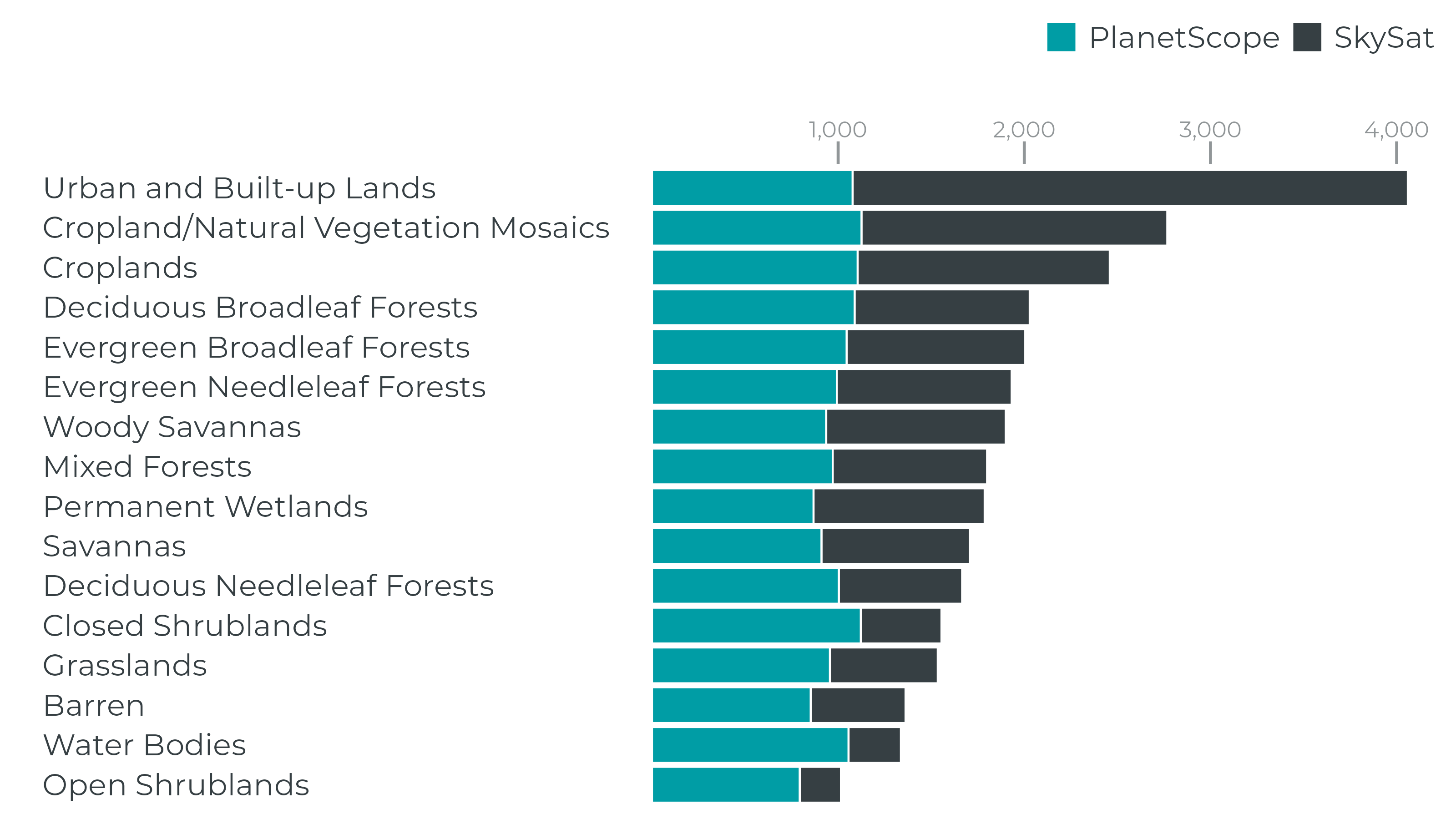
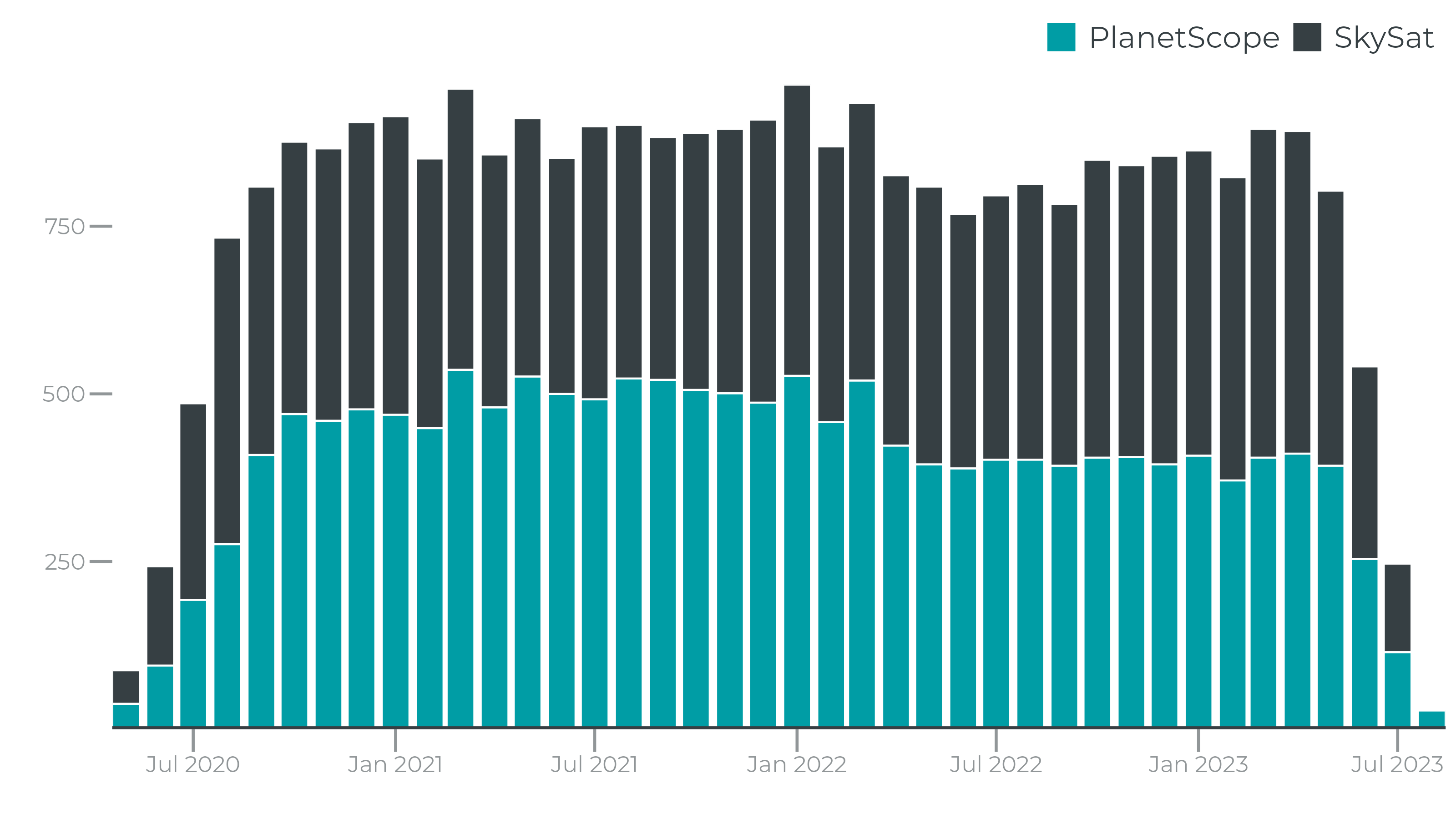
Performance¶
Supervised segmentation models are typically evaluated by comparing a model’s output to “ground truth” data and generating precision, recall and F1 metrics per class. For UDM2.1, we evaluated the model’s performance by evaluating each model on a hand-labeled geographically and temporally distributed ground truth dataset. Based on this analysis, we observed the following F1, precision and recall metrics:
PlanetScope
| Class | F1 | Precision | Recall |
|---|---|---|---|
| Clear | 0.909 | 0.871 | 0.951 |
| Snow | 0.770 | 0.777 | 0.763 |
| Cloud Shadow | 0.583 | 0.579 | 0.588 |
| Light Haze | 0.592 | 0.563 | 0.623 |
| Heavy Haze | n/a | n/a | n/a |
| Cloud | 0.945 | 0.929 | 0.961 |
SkySat
| Class | F1 | Precision | Recall |
|---|---|---|---|
| Clear | 0.848 | 0.816 | 0.883 |
| Snow | 0.803 | 0.780 | 0.87 |
| Cloud Shadow | 0.442 | 0.391 | 0.508 |
| Light Haze | 0.619 | 0.581 | 0.662 |
| Heavy Haze | n/a | n/a | n/a |
| Cloud | 0.924 | 0.905 | 0.944 |
Note
Planet publishes imagery globally. Our goal is to ensure the highest quality, but there can be anomalous behavior. If you observe poor quality, please contact your Customer Support Representative so Planet can address these issues with quarterly iterations of the model.
The Planet Engineering team regularly reviews cloud masks and identifies new scenes and add to the truth scene training set. Additionally, your reports of poorly performing scenes or regions are part of the feedback process to improve the truth training set.
Rate this guide: