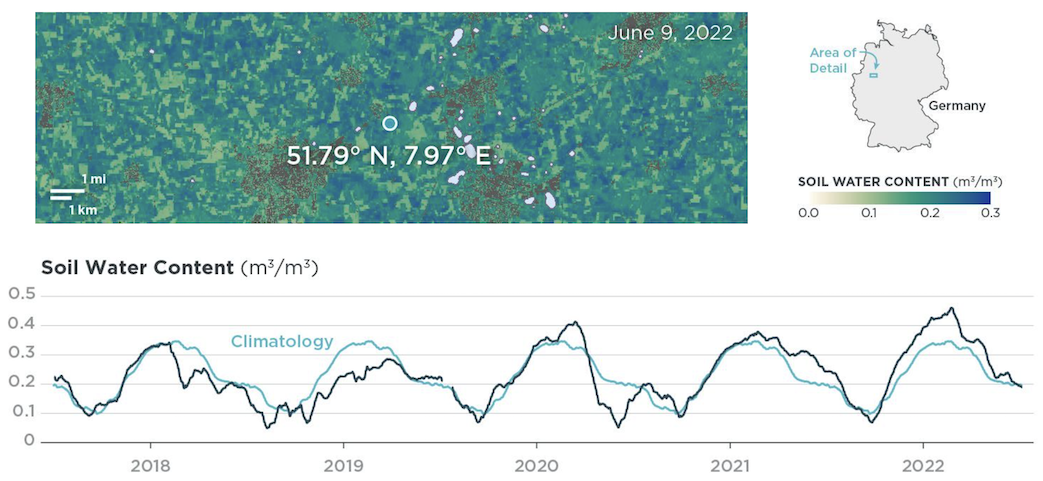
Soil water content is the amount of water between the soil surface and the groundwater level in the unsaturated zone. This ratio of water volume to soil volume is crucial for understanding soil health, hydrological processes, and drought conditions.
Planet's Soil Water Content (SWC) product offers near-daily measurements with spatial resolutions of 100 m and 1000 m. Based on passive microwave observations, our data is consistent across time and space, strongly correlating with ground data and accurately reflecting weather patterns. This makes it a cost-effective and low-effort alternative to physical soil water content sensors.
Note
Check out the technical specification for more detailed information.
Use Cases¶
Agriculture - You can use SWC data to develop models that assess field conditions, enabling more informed decisions about irrigation and field operations. The data is also used to make yield and crop quality predictions at both regional and field scales.
Drought Monitoring - Tracking conditions over years and decades, SWC data provides a baseline understanding of normal and abnormal conditions for any given region. Leading reinsurers and brokers use the data in more than 20 countries to help protect farmers from drought impacts.
Water Resource Management - Near real-time SWC data aids in monitoring complex water systems by offering insights into water demand and storage capacity. With over two decades of archive data, water resource managers can track droughts, measure soil saturation, and assess intervention effects.
Natural Disaster Risk Assessment - Models incorporating vegetation, weather, and SWC data offer detailed insights into risks for wildfires, floods, and other natural disasters. The data also helps evaluate the impact of ecosystem restoration projects. Compared to in-situ sensors, SWC data provides a cost-effective and less labor-intensive method for risk assessment and remediation tracking.
Basic Specifications¶
| Property | SWC 100 m | SWC 1000 m |
|---|---|---|
| Pixel size | 100 m | 1000 m |
| Temporal resolution | 137-365 observations per year | 137-365 observations per year |
| Geographical coverage | Global | Global |
| Latency | ~12 hours after overpass of the satellites | ~12 hours after overpass of the satellites |
| Data availability | 2017 - Present | 2002 - Present |
Data Access¶
- Access SWC data through our APIs:
- Check out these code examples:
- Jupyter Notebook that accesses SWC through the Planet Subscriptions API and creates data visualizations.
- Collection of custom scripts for Sentinel Hub, including scripts to visualize SWC in EO Browser and to calculate SWC anomalies.
- Explore sample data on Sentinel Hub.
Documentation and Training¶
- Explore the technical specification for more detailed information about the product.
- Learn more about the data validation.
- Follow the Intro to Soil Water Content course to get started.
Engage with Planet¶
Rate this guide: