Overview¶
Planet's Field Boundaries: A Planetary Variable¶
The Field Boundaries (FB) dataset is a Planetary Variable™ containing a set of polygons that represents the boundaries of agricultural fields.
Field delineation is the process that generates FBs by automatically tracing the boundaries of agricultural fields from Sentinel-2 satellite imagery with 10 m spatial resolution. An agricultural field is a spatially homogeneous land unit utilized for agricultural purposes, where a single crop is grown.
Planet’s Field Boundaries algorithm leverages the similarity of spatial, spectral, and temporal properties of pixels belonging to the same field. A deep neural network based on the popular U-net architecture is used to estimate the fields’s extent, boundary, and the distance of the segmented image pixels to the boundary. The estimated probability images are then combined into a single pseudo-probability image representing the extent of the fields.
In post-processing, the image prediction is converted into vector format, where each polygon represents the extent of a homogeneous agricultural field. The result is a set of closed vector polygons marking the extent of each agricultural field. Additionally, a quality assessment attribute is computed for each estimated FB polygon.
Inputs¶
For the specified TOI, Sentinel-2 satellite images are downloaded as well as the cloud masks. Sentinel-2 bands at 10 m spatial resolution are used, specifically B02, B03, B04, and B08.
The dataMask band is used for handling pixels with no-data. No-data pixels are all pixels which lie outside of the area of interest, all pixels for which no source data was found, and all pixels for which source data was found but are invalid.
Additionally, utilized alongside the native Sentinel-2 bands is s2cloudless, a machine learning algorithm for computing cloud masks and probabilities on Sentinel-2 imagery, sampled at 160 m resolution. They are available as Sentinel-2 bands named CLP (cloud probabilities) and CLM (cloud masks).
Field Boundaries Product¶
The current FB product output comprises two GeoPackages, as detailed in Table 2.
Table 1: Output
| Description | |
|---|---|
| fb | Field Boundaries derived from Sentinel-2 (10 m) |
| da | Data Availability map derived from Sentinel-2 (10 m) |
Product Specifications¶
Table 2: Field Boundaries product specification
| Data Resource | Field Boundaries |
|---|---|
| Source id | FIELD_BOUNDARIES_v1.0.0_S2_P1M |
| Type of product | Vector |
| Input data source | Sentinel-2 |
| Unit of measure | sqkm |
| Input data time interval | Output based on 1 month of data |
| Area of available coverage | Global |
| Temporal coverage | 2018 - onwards |
| Minimum mapping unit | Polygons with an area lower than 50 sqm are removed from the output. Polygons with Maximum Inscribed Circle Diameter (MICD) lower than 30 m are flagged as unreliable. |
| Delivery | GeoPackage through Subscriptions API |
Attributes¶
To facilitate characterization and interpretability of the resulting polygons, some attributes are added and a quality assessment attribute is computed for each estimated FB polygon. The attributes are listed in the following table and details on these are provided in the following Section.
Table 3: List of attributes added to each polygon of the FB dataset
| Attribute | Description | Attribute Type |
|---|---|---|
| Polygon ID | Each polygon in the resulting GeoPackage file has assigned an identification number. | int |
| Area | Polygon area in hectares. | float |
| Maximum Inscribed Circle Diameter (MICD) | MICD is an intuitive proxy for the width of a field, even in case of rotated and narrow-but-curved fields. | float |
| Circumference-Area ratio (CA ratio) | The ratio is calculated by dividing the circumference of a given polygon by the square root of its area. This ratio is then adjusted so that a circle corresponds to 0, and scaled so that a square corresponds to 1. | float |
| Quality Assessment attribute | The ‘qa’ attribute presents three values: 0: Polygons for which the validation scores are representative, i.e. with MICD > 30 m. 1: Polygons for which the validation scores are not representative, i.e. with MICD < 30 m. The quality for these polygons cannot be guaranteed. 2: Polygons that are intersecting the border of the data availability grid. | int |
Polygon ID
To facilitate downstream usage and indexing of the FB polygons, a unique integer identifier is assigned to each polygon. Uniqueness of the identifier is guaranteed only within a delivered GeoPackage file for a subscribed AOI. The same identifier will correspond to different polygons for different deliveries of the same AOI, or for different AOIs.
Area
The area of the polygon in hectares is included as an attribute (1 ha is 10,000 sqm). The area is computed before conversion to the common WGS84 coordinate reference system.
Maximum Inscribed Circle Diameter (MICD)
While the polygon area is a general descriptor for the size of a polygon, it carries no information about its shape. While evaluating and validating the FB product, it was observed that the shape of the polygon correlates more with the performance of the algorithm, rather than its size only. This has to do with the limitations in spatial resolution of the input imagery, which affect the minimum side, e.g. height or width, of the polygon that can be detected.
A very narrow but long polygon can have a large value of area, but nevertheless cannot be reliably detected by the algorithm due to its narrower side. MICD was identified to be a suitable metric for estimating the polygon width. The maximum inscribed circle is the largest circle which can be inscribed within the polygon, see Figure 2. MICD is added as an attribute, and used to flag polygons of uncertain accuracy.
 Figure 1: Illustration of an example of MICD for three different polygons. The central polygon is unlikely to be correctly delineated despite its non-negligible area, due its width, which is smaller than the Sentinel-2 spatial resolution. This highlights that area is not a good proxy for performance of the algorithm.
Figure 1: Illustration of an example of MICD for three different polygons. The central polygon is unlikely to be correctly delineated despite its non-negligible area, due its width, which is smaller than the Sentinel-2 spatial resolution. This highlights that area is not a good proxy for performance of the algorithm.
Circumference-Area ratio (CA ratio)
A normalized Circumference-Area ratio is added to each polygon to additionally describe its shape. The CA ratio can be used in conjunction to the Area and MICD attributes to identify polygons of circular shape, e.g. with CA ratio close to 0, of squared shape, e.g. with CA ratio around 1, or of more irregular shape, having CA ratio larger than 10. Examples of CA ratio are shown in Figure 3.
 Figure 2: Examples of polygons with different CA ratios: 0,08 (left), 1,05 (middle) and 45,47 (right).
Figure 2: Examples of polygons with different CA ratios: 0,08 (left), 1,05 (middle) and 45,47 (right).
Quality Assessment Attribute
A quality assessment (QA) attribute denotes polygons with known limitations. The attribute is an unsigned integer. The values presented in the table below are provided for the current version of the FB product.
Table 4: Values and their description of the QA attribute.
| QA Value | Description |
|---|---|
| 0 | Polygons for which the validation scores are representative, i.e. with MICD > 30 m. |
| 1 | Polygons for which the validation scores are not representative, i.e. with MICD < 30 m. The quality for these polygons is likely to be low. |
| 2 | Polygons that are intersecting the border of the data availability grid. |
The provided example illustrates four types of polygons. Polygons outside of the AOI are removed from the output. The remaining ones (depicted with solid and diagonal fill) intersect with the AOI and are therefore kept in the output. Polygons that are intersecting the border of the data availability grid are also kept in the output and are assigned a value of qa==2. We suggest removing such polygons from further analyses, as they only partially cover the underlying field.
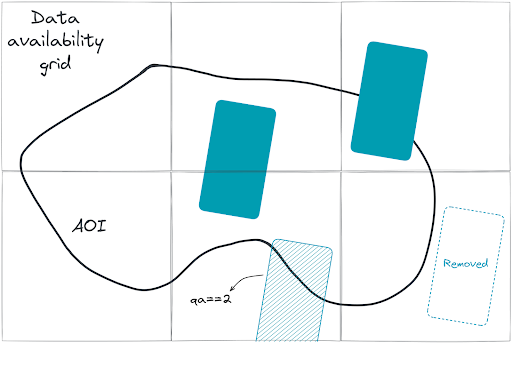 Figure 3: Example of four types of polygons.
Figure 3: Example of four types of polygons.
Data Availability¶
The additional output of the FB product includes a data availability map - a vector file suffixed _da. This map consists of a grid, representing the customer's AOI split during processing. Each grid cell has an attribute called ‘has_valid_observations.’ When this attribute is set to ‘false,’ it indicates that there were no valid Sentinel-2 observations available for the TOI defined by the customer. Consequently, the model failed to predict field boundaries within that specific grid cell. On the other hand, when ‘has_valid_observations’ is set to ‘true,’ it indicates that valid observations were available for the specific grid cell, leading to the successful production of field boundaries.
Table 6: Data availability map specifications.
| Attribute | Description |
|---|---|
| Type of product | Vector |
| Input data source | Sentinel-2 (10 m) |
| Input data time interval | Output based on 1 month of data (TOI) |
| Attribute | has_valid_observations |
Delivery¶
The output of FB is a GeoPackage (GPKG), which contains a vector data layer of delineated polygons representing fields within the chosen Area of Interest (AOI). Moreover, Planet provides a data availability map as an additional output.
FB is delivered through the Subscription API into a designated storage cloud bucket. Subsequently, the customer receives a notification regarding the availability of the data.
Table 7: Vector properties of FB outputs.
| fb | da | |
|---|---|---|
| Format | GeoPackage | GeoPackage |
| Geometry Type | Polygons | Polygons |
| Spatial reference | EPSG:4326 | EPSG:4326 |
| Delivery | Vector data file containing polygons | Vector data file containing polygons |
| Attributes of each polygon | polygon_id, area_ha, micd, ca_ratio, qa | has_valid_observations |
Methodology¶
Planet carries out the following steps to produce boundaries of the agricultural fields:
- split the AOI into a grid to parallelize and speed up processing
- retrieve remote sensing imagery for the time period of interest
- spatially coregister the multiple images
- inference of the pre-trained deep learning model on the input imagery, obtaining pseudo-probability maps of field boundary estimates
- post-processing of the pseudo-probabilities to obtain a single vector file of merged agricultural field boundaries
- compute attributes
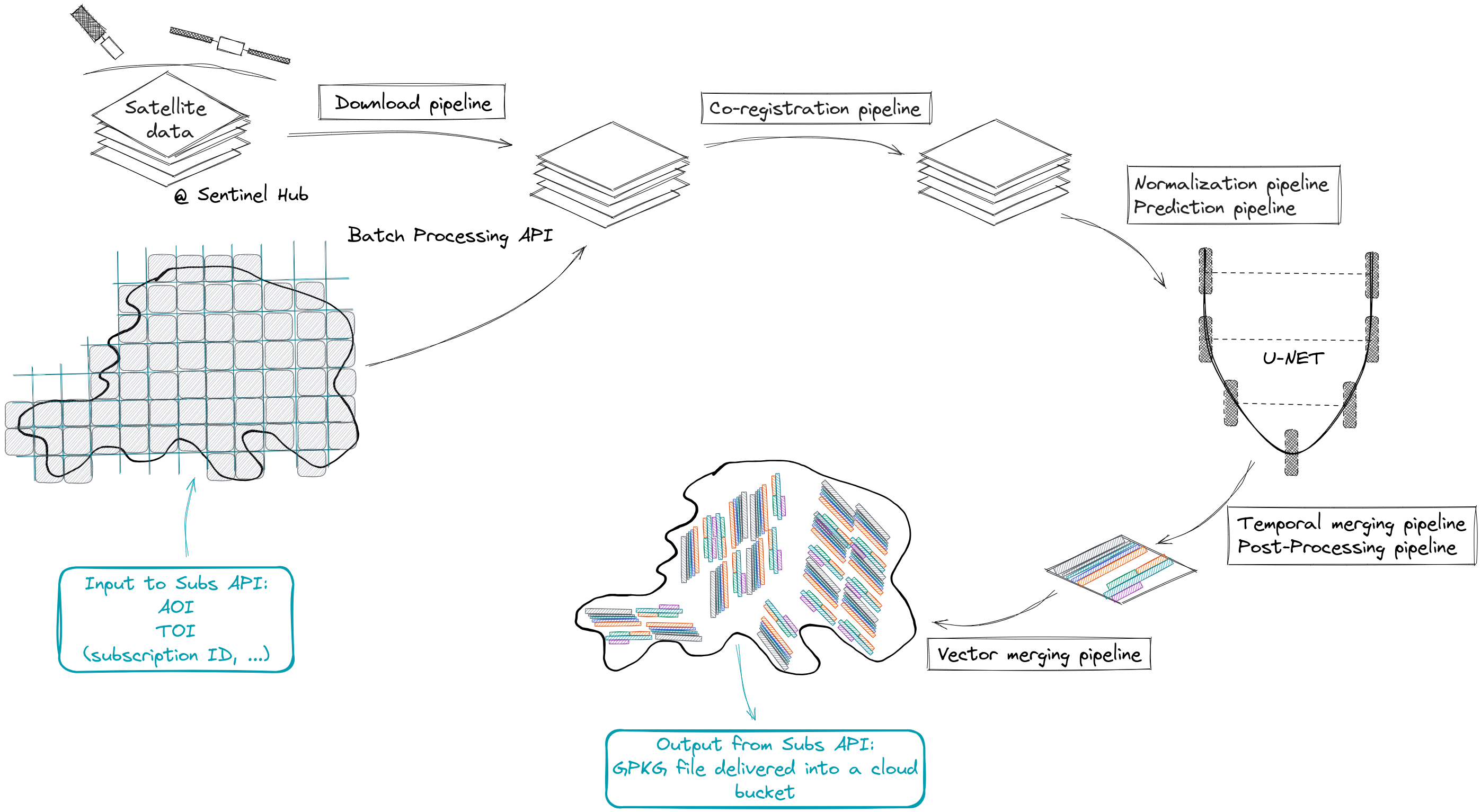 Figure 4: Production pipeline.
Figure 4: Production pipeline.
The AOI is split into a regular grid, which allows massive parallelization of the processing. For each grid cell, Planet performs data download, pre-processing, model prediction and post-processing. Predictions across all grid cells are merged in a complete map during the final stages of the process.
Accurate field delineation requires clear-sky observations. For the selected TOI, satellite images, as well as cloud and no-data masks are downloaded for each grid cell using Sentinel Hub batch API. Estimates of cloud coverage are produced for each grid cell. If cloudless scenes exist, i.e. with a cloud coverage below 10%, only these are considered to generate a consensus. If no cloudless scenes are available, a consensus is generated using all scenes in the grid cell, by only considering pixels not covered by clouds. This is performed in order to ensure that clouds and related artifacts don't affect the estimation of boundaries. When no valid Sentinel-2 observations are available for a specific grid cell during the TOI defined by the customer, the model fails to predict field boundaries within that specific grid cell. In the additional output Data Availability map these grid cells have the value of the "has_valid_observations'' attribute set to “false”.
Co-registration of the input satellite time-series within a grid cell is applied to reduce frame-to-frame misalignments, and therefore to reduce noise when creating a temporal consensus.
Each input Sentinel-2 band is normalized using statistics pre-computed over a large area. Following normalization, a pretrained U-net network, inspired by Waldner and Diakogiannis (2020), is employed to infer extent, boundary and distance to boundary of each detected agricultural field for each input observation of the time-series. The U-net network has been trained on pre-processed data from the EuroCrops dataset in a separate training phase. As the model is not trained on temporal data, and significant differences may exist in predictions made between different observations, different temporal predictions are temporally merged into a single prediction. The resulting image has continuous values that can be treated as a level set function, and can therefore be thresholded to obtain smooth contours. In the final step, Planet merges vector predictions over grid cells (and over UTM zones), resolving the duplication of vectors in overlapping regions of neighboring grid cells.
To correctly produce field boundaries, an assumption about the dimensional limits of the polygons needs to be made. Polygons of area lower than 50 sqm, i.e. half the size of a Sentinel-2 pixel, are removed from the database. These are noisy predictions mostly due to post-processing. Very large and very long polygons that spread over large distances may also present an issue for producing accurate results. Maximum Inscribed Circle Diameter (MICD) is the largest circle which can be inscribed within the polygon, and is an intuitive proxy for the width of a field. We mark polygons as unreliable (qa value 1) in Quality Assessment attribute if their MICD is less than 30 meters, which essentially means their minimum/shorter side is less than 30 meters.
For each estimated polygon, Planet computes attributes that facilitate the characterization and analysis of the results for downstream applications. The provided attributes for each polygon are: an ID, area in hectares, MICD, which is used to compute the Quality Assessment attribute, and the Circumference-Area ratio. These attributes can be combined to filter polygons of lower quality by the end user.
Validation¶
We evaluated the FB product extensively on the largest source of reference data in Europe, i.e. EuroCrops dataset. The dataset is based on GSAA polygons, which have known quality limitations (described in Utility of AI4Boundaries and EuroCrops as training datasets for field delineation blog post), leading to under-estimation of the delineation performance. However, such a dataset allows us to evaluate the algorithm on a diverse set of samples, in terms of sizes, shapes and semantic definitions. As can be expected due to the limitations of the spatial resolution of the input imagery, the performance increases as the size of the fields increases, with median IoU scores greater than 0.8 for fields having minimum side larger than 150m, reaching a IoU up to 0.98 for for fields with minimum side larger than 240m.
Note
Check out the validation report for more detailed information.
Limitations¶
When assessing the FB dataset it is crucial to consider the following points about the model:
- TRAINED FOR DELINEATING ARABLE LAND: the deep learning model was trained to delineate arable land;
- TRAINING DATA SOURCE: The model was trained on GeoSpatial Aid Application (GSAA) data, annual crop declarations made by European farmers for Common Agricultural Policy (CAP) area-based support measures. This data is not always aligned with boundaries seen on the ground at a certain acquisition and can be incomplete and outdated, since national paying agencies are not yet obliged to maintain such a dataset;
- RESOLUTION LIMITATION: Predictions are based on Sentinel-2 imagery with a 10 m spatial resolution.
The following limitations have been identified:
-
The majority of the EuroCrops data covers central and northern European countries, therefore the model has been primarily exposed to, and trained on, data from these regions.
-
The model was trained to delineate agricultural areas (e.g., annual crops), therefore the quality of field boundaries over grassland (pastures, meadows) and areas with permanent crops (orchards, vineyards, olive groves) is lower.
-
The FBs are constructed from cloud-free observations over the AOI from the time interval of one month. In some cases over cloudy areas the single-month approach might not produce fields over some areas, as shown in the availability maps. A vector file containing a data availability map that highlights areas lacking valid Sentinel-2 observations for field boundary prediction is provided. It assists customers in identifying data gaps.
-
The performance is less favorable in arid regions, particularly evident in Mediterranean countries, attributed to the challenge of less distinct field boundaries in arid landscapes, and a lack of training samples in such areas.
-
Due to the model being based on Sentinel-2 imagery with a 10 m resolution, predictions for fields with MICD less than 30 m may be of low quality or, in some cases, may be missing. For this reason, a data quality flag will identify such polygons.
-
Some resulting field boundaries might be joined at either end of the field as a result of the super-resolution layers. This generates larger field boundaries that are however not fully disconnected.
-
Predictions might present holes, which in some cases can correspond to actual non-arable land objects, such as trees, large boulders or wind mills, but can also in some cases correspond to uncertain boundaries not completely detected.
 Figure 1: Example of undesired holes due to uncertain boundaries on the left, while the right figure shows holes that correctly detect non-arable land objects.
Figure 1: Example of undesired holes due to uncertain boundaries on the left, while the right figure shows holes that correctly detect non-arable land objects.
- The FB dataset might not be suitable for variable rate application, as the polygons can not compare to digitized polygons in terms of quality and size, due to limitations of the spatial resolution of the input Sentinel-2 imagery. They tend to be systematically smaller than the ground truth field boundaries, and they exhibit rounded corners.
Frequently Asked Questions¶
What imagery is used to create the Field Boundaries PV and why?¶
The first version of Field Boundaries uses data from Sentinel-2 with 10 m resolution. Historically, FBs were created by Sinergise within an European Commission funded research project on Sentinel-2, and the results for large fields are reliable even with using Sentinel-2 data.
Which TOI is recommended?¶
We generally suggest choosing a month that represents the early growing phase of crops, such as May or June for the northern hemisphere.
Does the Field Boundary PV work for smallholder farms?¶
V1 of the Field Boundary PV is not well suited to smallholder farms due to the 10m resolution of the Sentinel data that was used to create this first version of the product.
Field Boundaries fault towards underestimation of area versus overestimation. How much area is underestimated on average?¶
There is high variability depending on the shape and size of the polygons, but on average around 10 %.
We are continually working to improve our technical documentation and support. Please help by sharing your experience with us.